Expresso client code: the inner workings - Part 1 XML connection client code in java
About client code
Client code is useful. It enables Expresso parser to be accessed pragmatically. Basically, you set up rules for parsing or web service modules using the GUI and then remotely access those rules from your own project using client code. This makes client code powerful!
Various types of
client code
Client code comes in different languages. We are currently aiming at increasing it's usefulness by adding new languages so that you can use Expresso parser whether you are a java, C++, Ruby or javascript developer. This list will keep growing and we are eager for suggestions as to new languages which we can support!
There are two types of client code: XML connection code and Web service module code. The former allows you to parse an XML file using your prepared rules. The latter allows you to consume a prepared vendor web service.
How client code
works
Client code connects to Expresso using HTTPS. It passes paramaters into a HTTPS request, which Expresso processes, and it gets a result back.The values returned from XML connection client code
A three dimensional array is returned from an XML connection. Most times you will only need one or two dimensions of this array.The outer array is a list of rules which you parsed. If you only parsed using one rule, there will only be one item in this array.
So, we start with an array which has one element for each rule parsed. If we wish to handle the results of any one rule we simple choose that element from the array.
For example, if you are parsing three rules and you wish to process the results of the first rule, simply use the first element of this array.
Each rule element contains a 2 dimensional array.
This middle array contains each return type.
So, what are return types?
Simple rule - 1 return type
Well, if you have a rule which says "get element address and return it" you are returning each address element value. Your rule has one return type - the address.
In this case, you will have a one element array. The element will simply be a list of addresses.
Complex rule - multiple return types
If you then say "get element address and return it AND also get element postcode" you are getting two return types - address and postcode. So, the results will contain a list of addresses and their corresponding postcodes.
In this case, you will have a two element array. The first element will be a list of addresses. The second element will be a list of postcodes.
As you can imagine, the inner array is this list of returns e.g. the list of addresses.
Here is an example of a simple rule....
<books>
<book>
A brief history of everything
</book>
<book>
History of Europe 1900 - present
</book>
</books>
We create a rule for this XML file. Our rule is as follows:
Return the text value of any element called book.
We then call client code to run our one rule search. The results are a three dimensional array as follows:
1. Our outer array is the rule. It will have one element as there is only one rule. We take this element and look inside. It is a 2 dimensional array - the middle array.
2. The middle array will have 1 element in it as we are only returning one return type i.e. book value. We take this element and look inside. It is an array.
3. This inner array contains the value of each book element. i.e. A brief history of everything, History of Europe 1900 - present.
We can loop through this array and print out the values.
The values returned
from web service connection client code
Web service connection code is simpler. We return an array containing two elements. The first element is the XML response from the web service. The second element is the parsed XML response as an array of results.
XML Connection client code in java in more detail
The steps involved in the client remote connection
There are three major parts to this client code
These are:
- Setting parameter values
- Sending a HTTPS request
- Reading the response
Setting parameter values
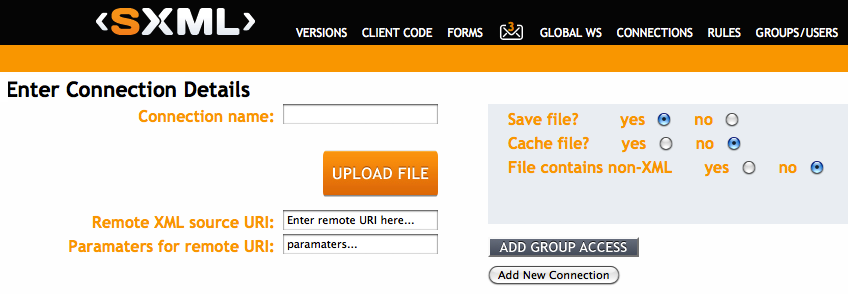
We set various values for the parameters. Some of these are required such as the username, password, connection name and company of the sender.
There are then some optional parameters which allow you to specify the location of the XML file, the XML file itself (if on your system) and whether or not you wish to use a cached version of the file.
There are also advanced parameters which enable you to do things such as specific particular rules, supply parameters and sort results.
Part 1: parameters
required parameters
- Username - the name you use to login to the website.
- Password - the password you use to login to the website.
- Company - the company name you use to login to the website.
- ConnectionName - the name of the XML connection you wish to parse. This is the name you supplied when creating the connection on the website.
Optional simple paramaters
- xml source - the source of the XML you will parse. You have three choices here: client, web or server.
- You can use an XML file which you supply with the request i.e. it is uploaded. This is client code. It allows you to supply a new XML file with each request.
- You can use a web-based XML file. This is called web mode. When you set up a connection on the website you have the option to supply a URL rather than uploading an XML file. Now you use this URL again to access the XML file. Since the URL has been saved with your account you do not need to supply it.
- In most cases the XML file is uploaded to the website when creating a connection and this XML file stored on the sever is used for parsing. This is server mode.
- If no mode is supplied server mode is used by default.
- XML File - If using client mode, the XML file is supplied with the request. This field is it's location on your local system and it is specified here so that the file can be loaded as a string and sent with the request. This is only required with client mode.
- caching - This specifies whether or not the file will be parsed using a cached version. It defaults to false.
- You can use an XML file which you supply with the request i.e. it is uploaded. This is client code. It allows you to supply a new XML file with each request.
- You can use a web-based XML file. This is called web mode. When you set up a connection on the website you have the option to supply a URL rather than uploading an XML file. Now you use this URL again to access the XML file. Since the URL has been saved with your account you do not need to supply it.
- In most cases the XML file is uploaded to the website when creating a connection and this XML file stored on the sever is used for parsing. This is server mode.
- If no mode is supplied server mode is used by default.
optional advanced parameters
- mode - This allows you to parse by a selection of rules rather than all the rules associated with that connection. You can choose to parse a connection with all it's associated rules by using mode = all. This is the default. You can specify one or more rules to parse with by listing these rules as the mode. Each rule should be separated by &.
- sortBy - This allows you to sort the results in ascending order. For simple rules, sortBy should specify the rule name and 0 as there is only one possible return type to sort by. Otherwise choose which of the return types to sort by e.g. if returning the title and price of a list of books, choose 0 to sort by title and 1 to sort by price.
- dynamic Parameters - These can be used to modify rules on the fly depending on user input. You can add a new value to a rule and this value will be used with the rule. e.g. You can have a rule which searches for tag = book and price is > 5.00. You can then add a parameter of 10.00 to the rule and the rule will become tag = book and price is > 10.00.
- URL parameters - if you are using a web based XML source and the URL changes with each request you can supply URL parameters to dynamically create the URL where the XML file is found.
Part 2: sending the
response
The response is send via HTTPS to the Expresso parser and the results are returned.
Part 3: Dealing with
the returns
The returns are checked for errors and then the 3 dimensional array is looped through and the values are stored and printed out.
Part 4: Possible
error messages
ERROR CODE 1: incorrect user details
This means that your username, password or company is not correct.
ERROR CODE 2: userFileStore is missing
This error means that the username or company you supplied does not exist on the server. Check these parameters and contact SXML Help if this happens.
ERROR CODE 3: file is missing from request. Please ensure this field has been added
This means that the fileForXMLUpload parameter is blank and that you have chosen client as your XML file source. Ensure that the correct local location for the XML file to be uploaded is supplied.
ERROR CODE 4: remote file name on server does not exist at this location
The file you are trying to parse does not exist on the server. This can be caused by choosing not to save the file when creating an XML connection or by deleting an XML connection. Check that you have correctly spelled the XML connection name supplied and that this connection exists and that the 'save file' option is set to true.
ERROR CODE 5 - parsing error
This means that there was an error parsing this XML file. The error details are supplied.
ERROR CODE 6: file not saved on remote Server. Please login to web page to upload file
The file you are trying to parse does not exist on the server. This can be caused by choosing not to save the file when creating an XML connection or by deleting an XML connection. Check that you have correctly spelled the XML connection name supplied and that this connection exists and that the 'save file' option is set to true.
ERROR CODE 7: cache could not be located
This means that the cache related to the XML file does not exist. Ensure that you choose 'caching' as true when creating the connection.